Execution Flow
Execution flow enables a Provider Data Scientist /Business Analyst to design the Data Pipeline in a specific sequence
Note : The other execution options shown in the below screenshots are not available for GCP environment.
File Validation
This feature enables a Provider Data Scientist /Business Analyst to validate the raw input file ingested into the Bristlecone NEO® Data Lake.
- Empty File Check : Validates if the raw input file is empty
- Missing Column Header : Validates the raw input file for columns without a header
- Duplicate Column Check : Validates the raw input file for duplicated columns
Configuring File Validation
Step 1 : Click on File Validation button as shown below
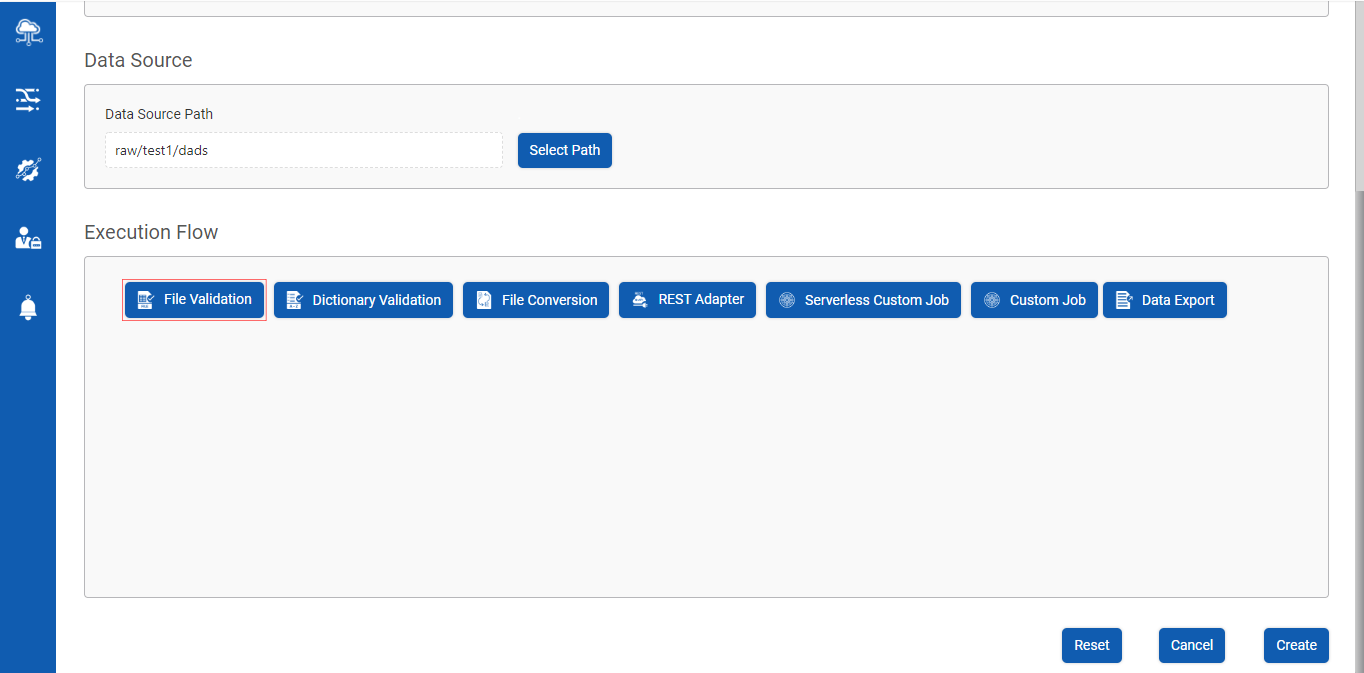
Step 2 : Click on File Validation tab as shown below :
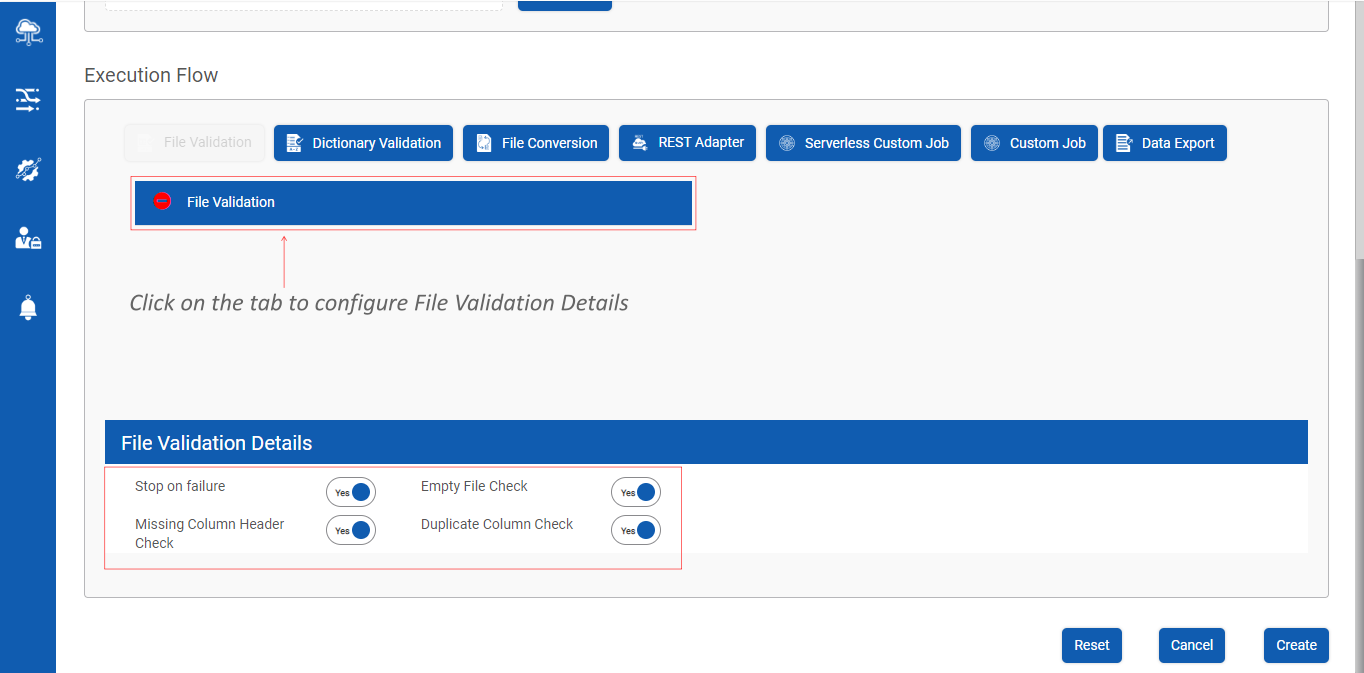
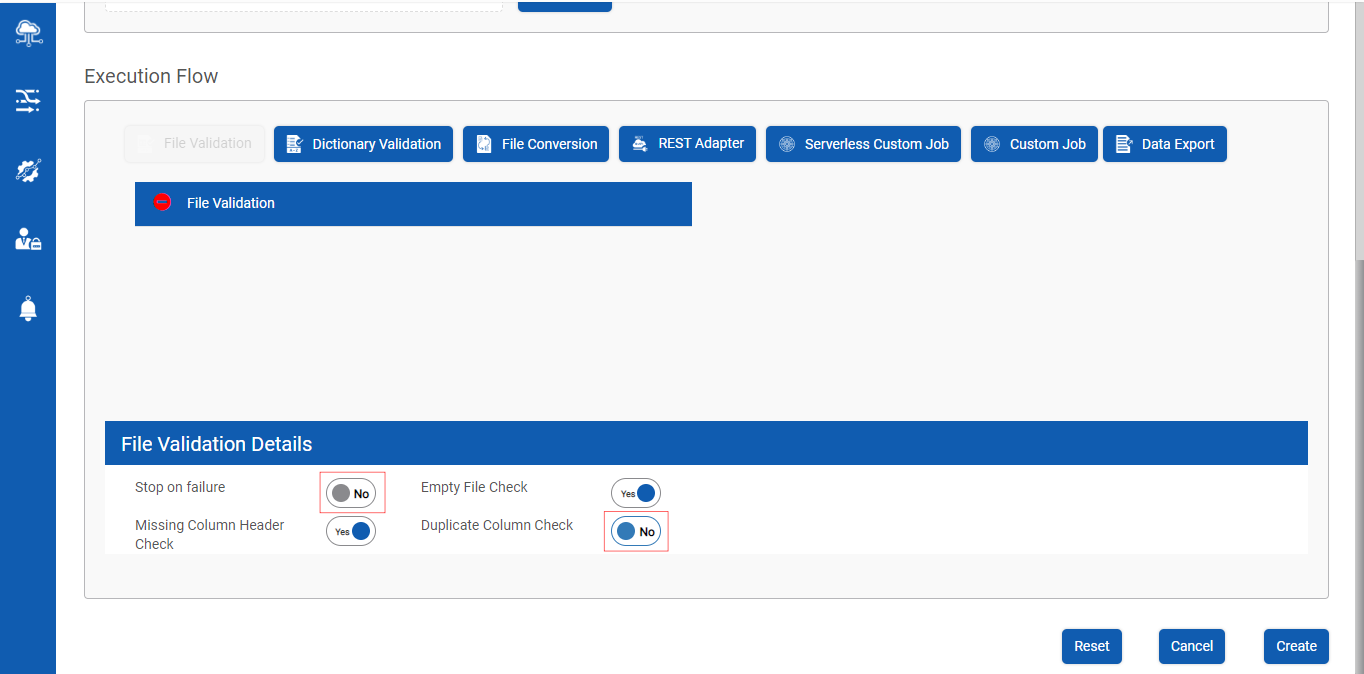
Step 3 : Configuring File Validation Details
- Stop on Failure : This feature stops the execution of the Data Pipeline when the File validation fails
- Empty File Check : This feature checks if the input file is empty
- Missing Column Header Check : This feature checks for columns which do not have headers
- Duplicate Column Check : This feature check if there are any columns duplicated in the input file
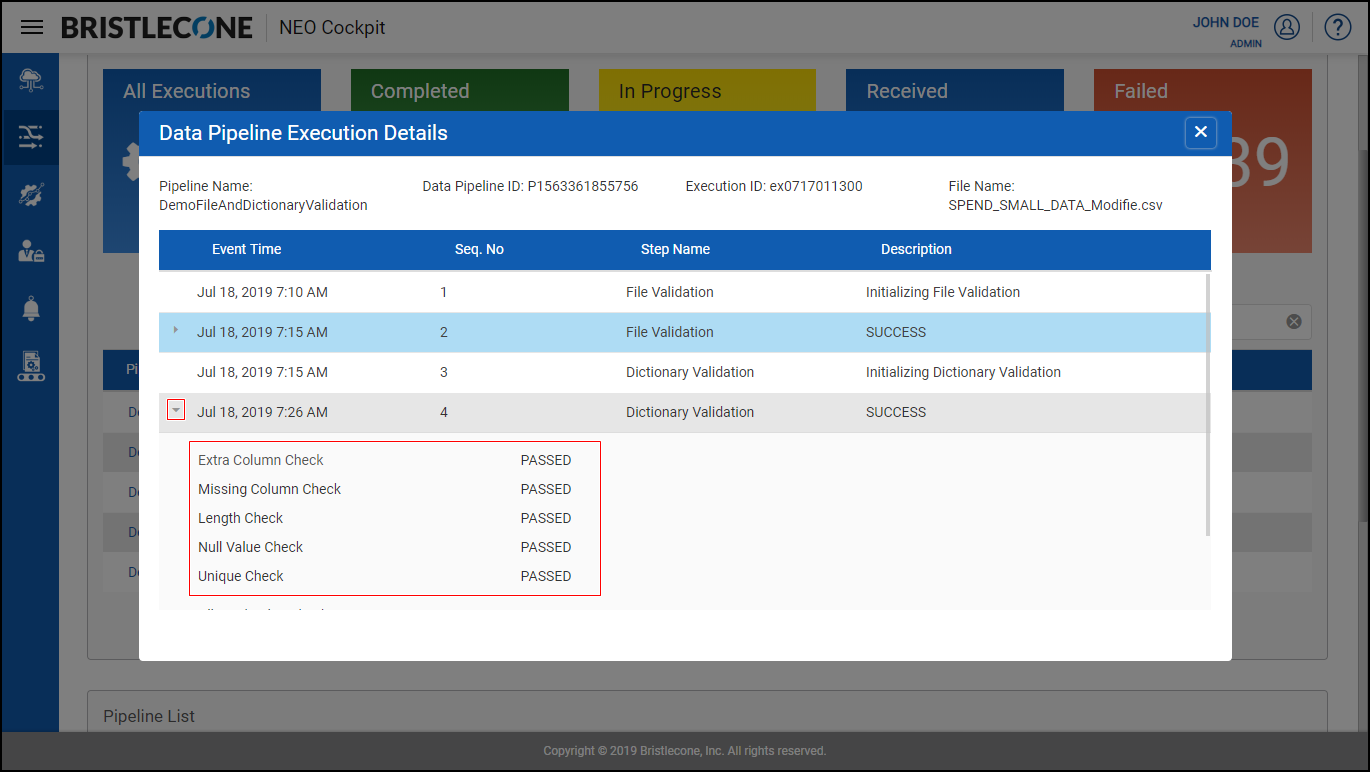
Post Data Pipeline Execution , click on Data Pipeline Execution Details to receive a pop up. Expand File Validation Step to find the dictionary validation details
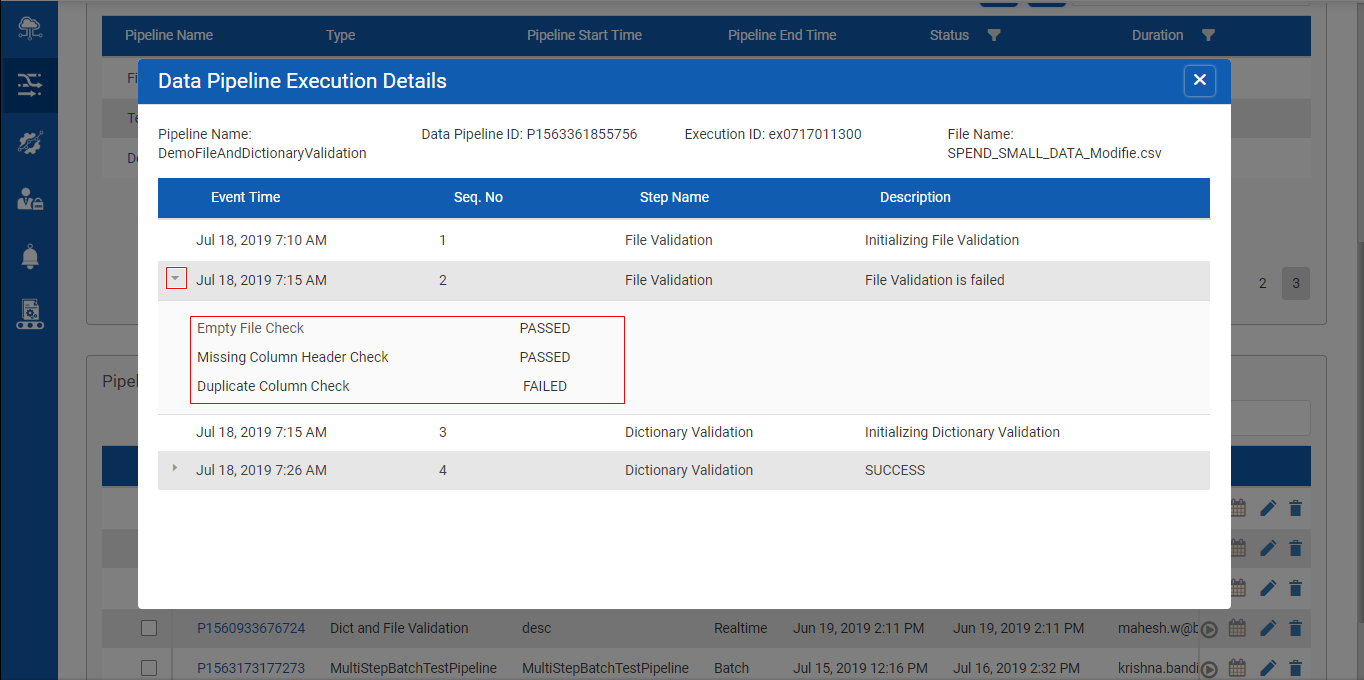
Note : User can enable /disable these toggle buttons as per the requirement
Dictionary Validation
This feature enables a Provider Data Scientist /Business Analyst to validate the raw input file and stop the data pipeline from triggering, if the file turns to be invalid based on the following conditions.
|
S.No |
Feature Based Test |
Status |
Comments |
|
1 |
Extra Column Check |
PASS |
No extra column |
|
2 |
Extra Column Check |
FAIL |
Input file has columns which are not defined in dictionary |
|
3 |
Missing Column Check |
PASS |
No missing column |
|
4 |
Missing Column Check |
FAIL |
Input file has one / more missing columns |
|
5 |
Null Value Check |
PASS |
No nullable values found in the non-nullable columns |
|
6 |
Null Value Check |
FAIL |
Null values found in the non-nullable columns |
|
7 |
Allowed Value Check |
PASS |
A column has only allowed values and (nulls if marked as nullable) |
|
8 |
Allowed Value Check |
FAIL |
A column has values other than allowed values |
|
9 |
Unique Value Check |
PASS |
No duplicates |
|
10 |
Unique Value Check |
FAIL |
Added duplicates entries found in the input file Note: Applicable for columns marked as Unique in the Data Dictionary |
|
11 |
Data Type Check |
PASS |
No difference in Data Types |
|
12 |
Data Type Check |
FAIL |
Added different data type included which has not been mentioned in the Data Dictionary |
|
13 |
Scale and Precision Check |
Not Implemented |
Will show status message as SKIPPED |
|
14 |
Value Check |
Not Implemented |
Will show status message as SKIPPED |
|
15 |
Length Check |
PASS |
Length of a given attribute in the input file matches the length specified in the associated Data Dictionary |
|
16 |
Length Check |
FAIL |
Length of a given attribute in the input file is a mismatch with the length specified in the associated Data Dictionary |
Configuring Data Dictionary Validation
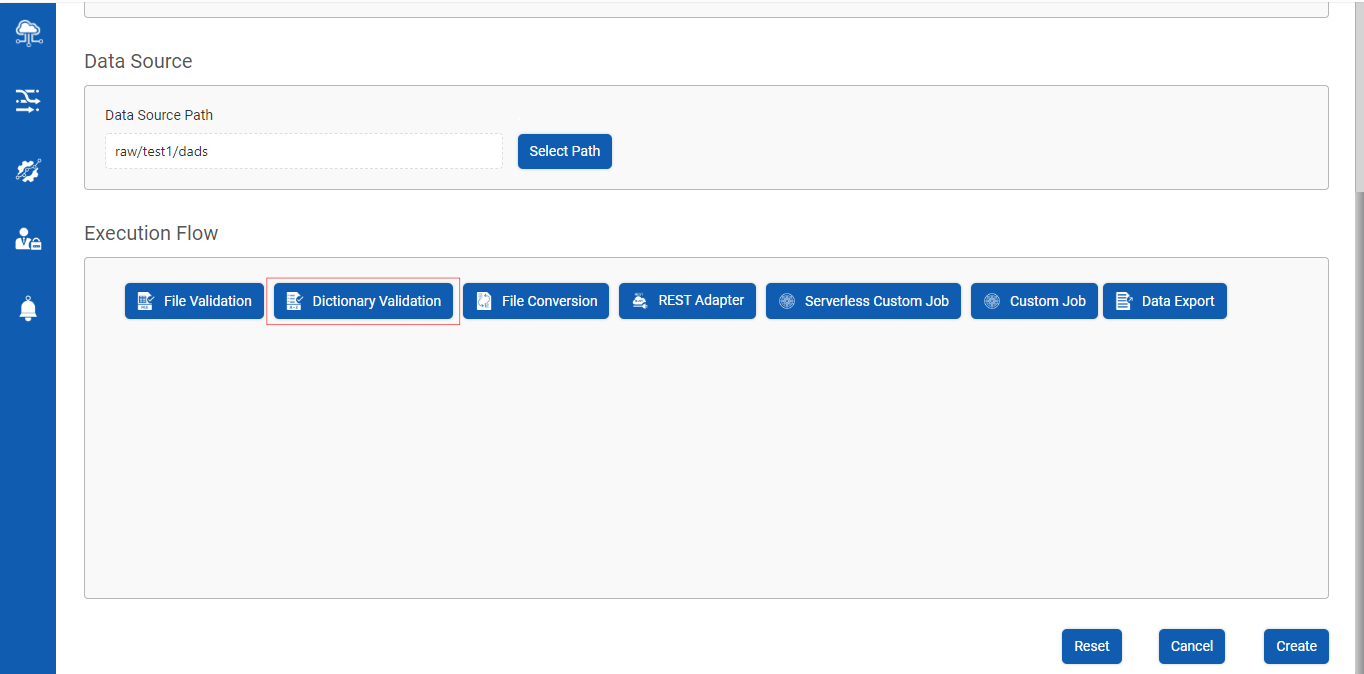
Step 1 : Click on Dictionary Validation button during the creation/updating the Data Pipeline as shown below :
Step 2 : Click on Dictionary Validation tab as shown below :
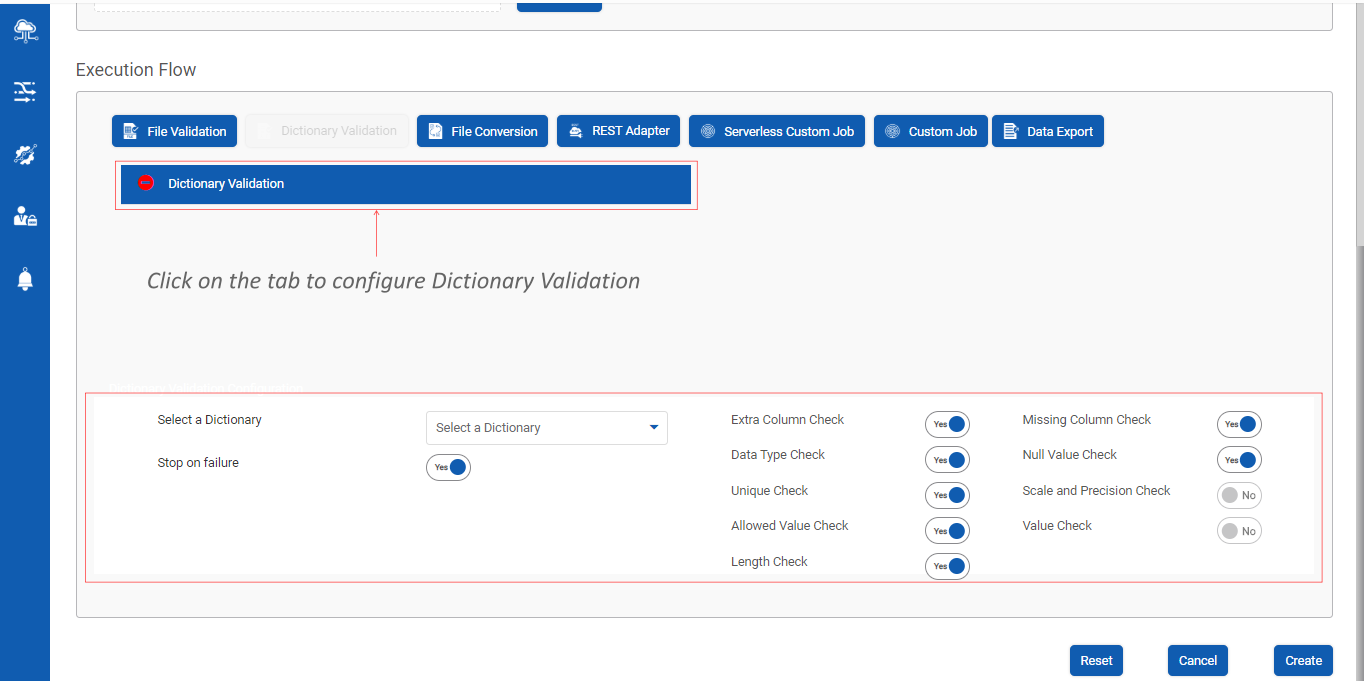
Step 3 : Configure Dictionary Validation Details:
Dictionary Validation Details contain the following toggle buttons that allow the user to enable or disable the following features
- Stop on Failure : This feature stops the execution flow of the Data Pipeline when the raw input data file of the specific data pipeline fails during Data Dictionary Validation
- Extra Column Check : This feature compares the input file with the associated Data Dictionary and checks for extra columns in the input file
- Data Type Check : This feature checks for columns and their associated data types as per the specific data dictionary connected to the input file
- Unique Value Check : This feature checks if the data dictionary has unique values
Note : Unique Value Check is case sensitive
- Allowed Value Check : This feature checks for allowed values for various columns in an input file
Ex : A column called currency has all the values in $ , upon choosing allowed values for the currency column user can have other currency formats such as INR , dinars ,euros, pounds.
- Length Check : Checks for the length of the value in all the columns mentioned in the associated Data Dictionary for the specific input file
Note : Applicable to selected data types such as : String, Character, Integer
- Missing Column Check : Compares the input file with the associated Data Dictionary and checks for the missing columns [ if any ] in the input file
- Null Value Check : Checks if null values are allowed for a specific file as per the associated data dictionary
Steps to configure Dictionary Validation
Step 3a : Select the specific dictionary associated with the input file as shown below :
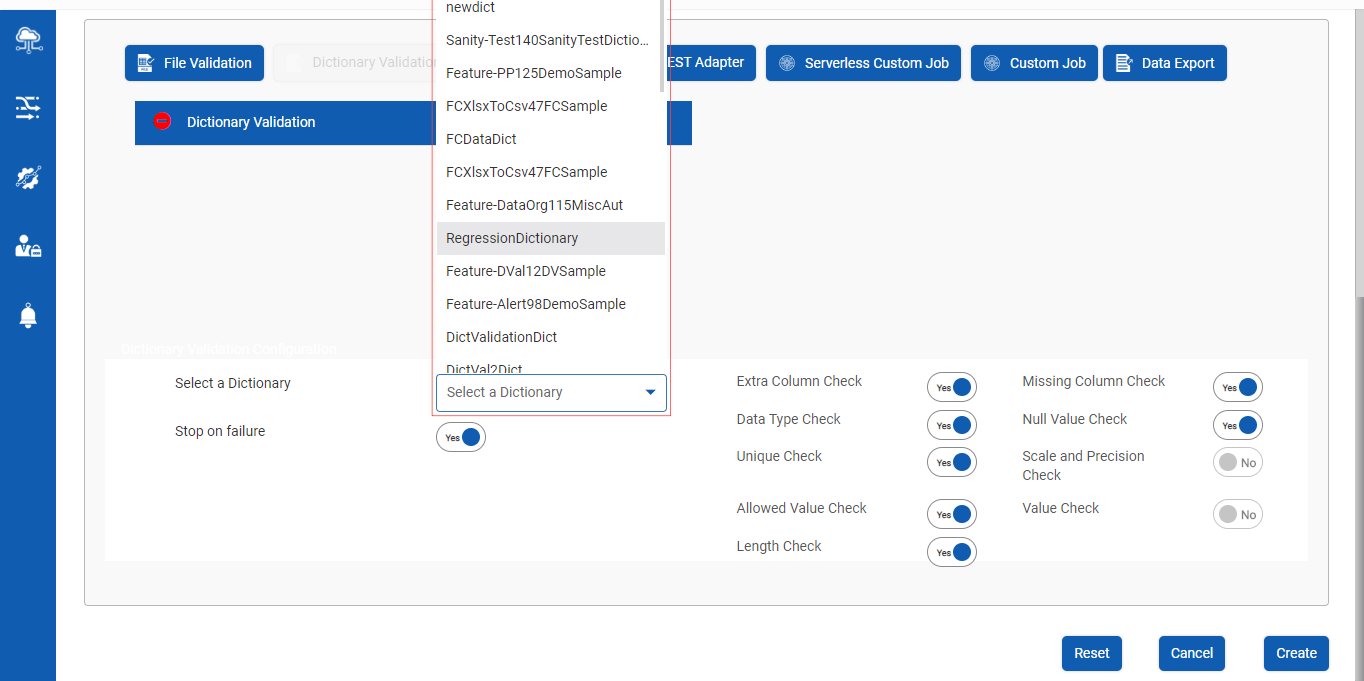
Step 3b : Select the toggle buttons to apply various validations on the associated dictionary of the specific input file as shown below:
The screen capture below shows a few of the toggle buttons activated for illustration purposes
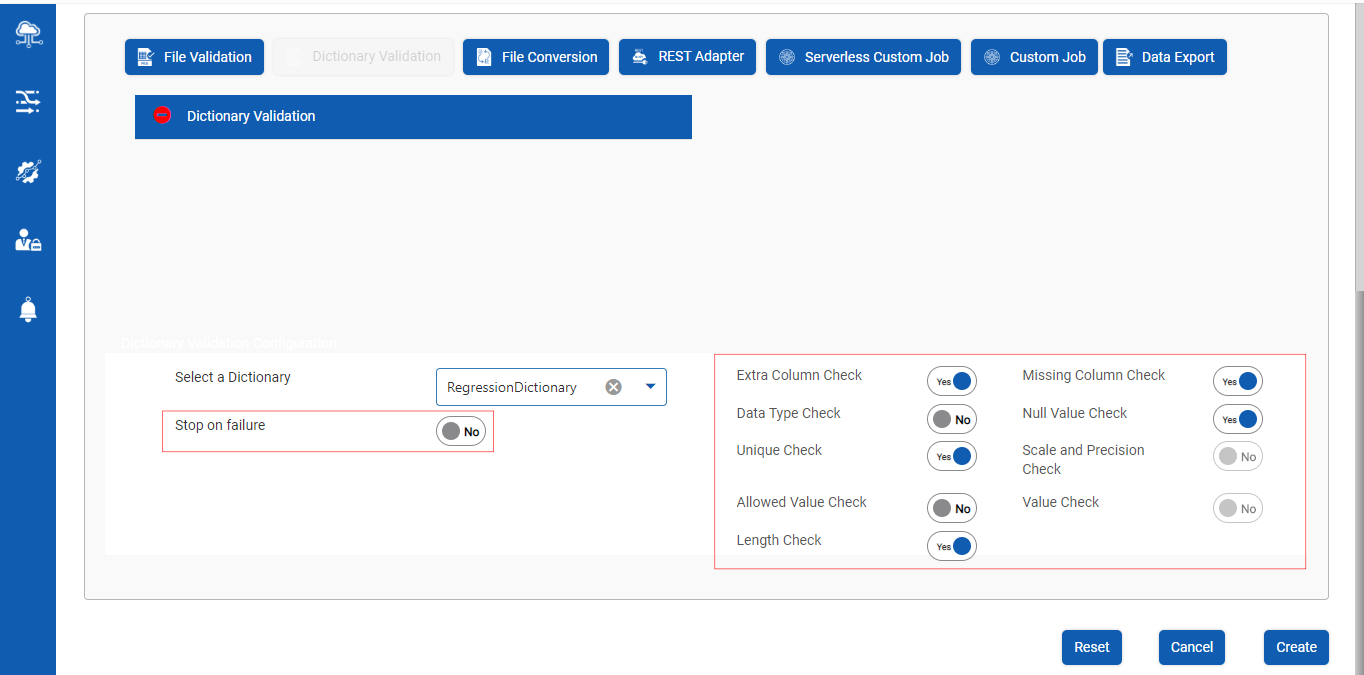
Step 4 : Post Dictionary Configuration, click on Create button to complete Dictionary Validation flow
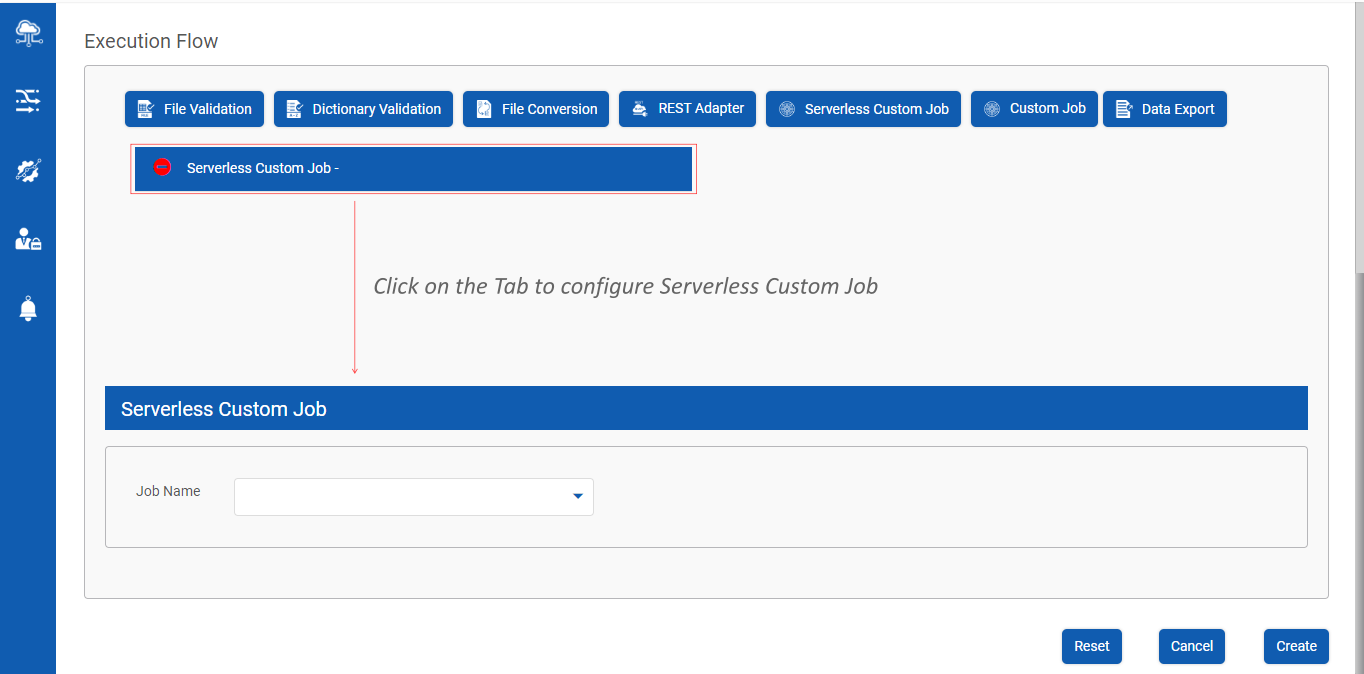
Enables a Provider Data Scientist to execute a pre-configured AWS glue script as a part of the Data Pipeline Execution Flow
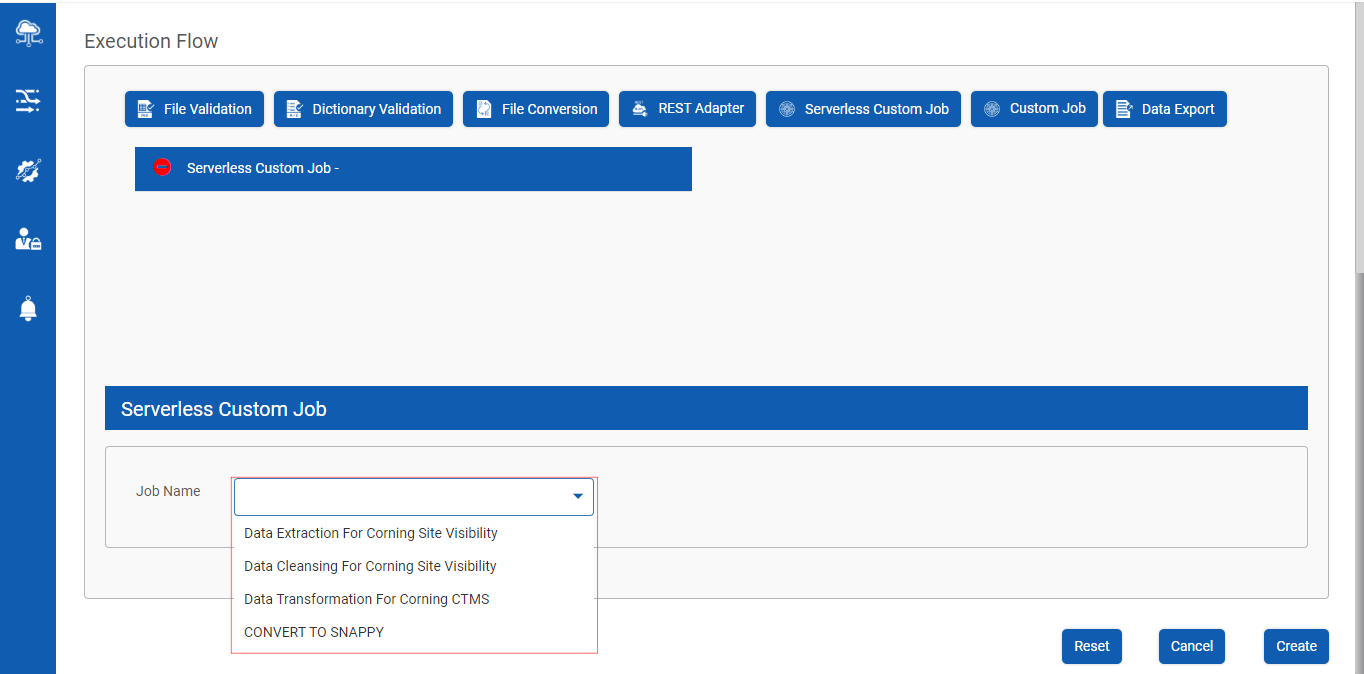
Post Data Pipeline creation, click on Serverless Custom Job as shown below
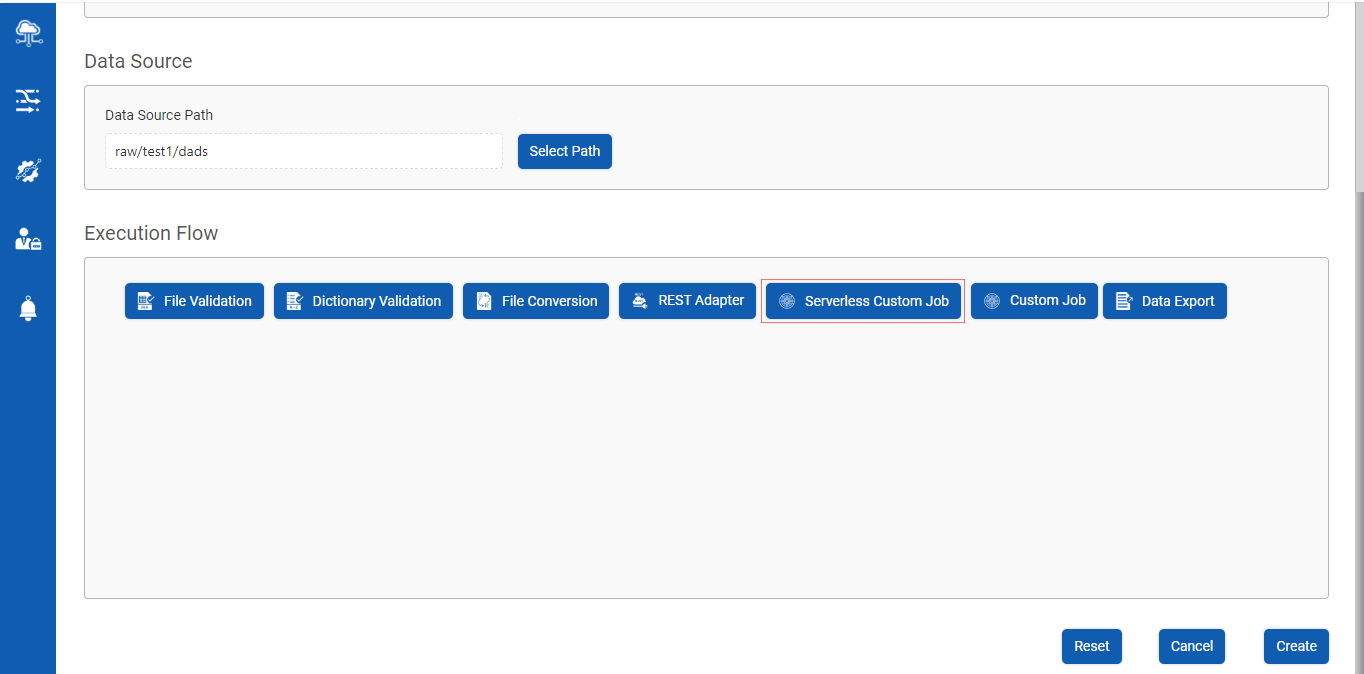
Click on Serverless Custom Job tab to add Jobs as shown below