Creating a Data Pipeline
Designing a Data Pipeline : On File Drop
A Data Pipeline can be designed as follows:
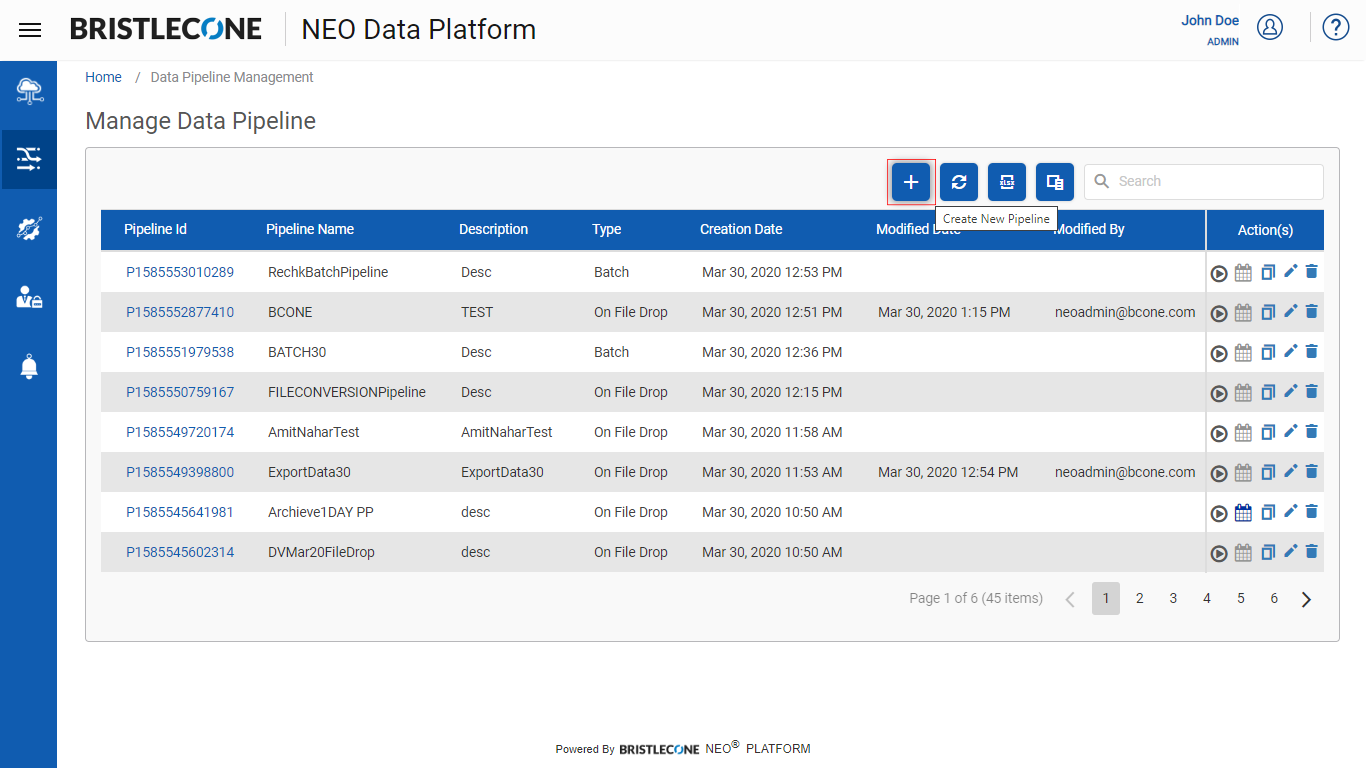
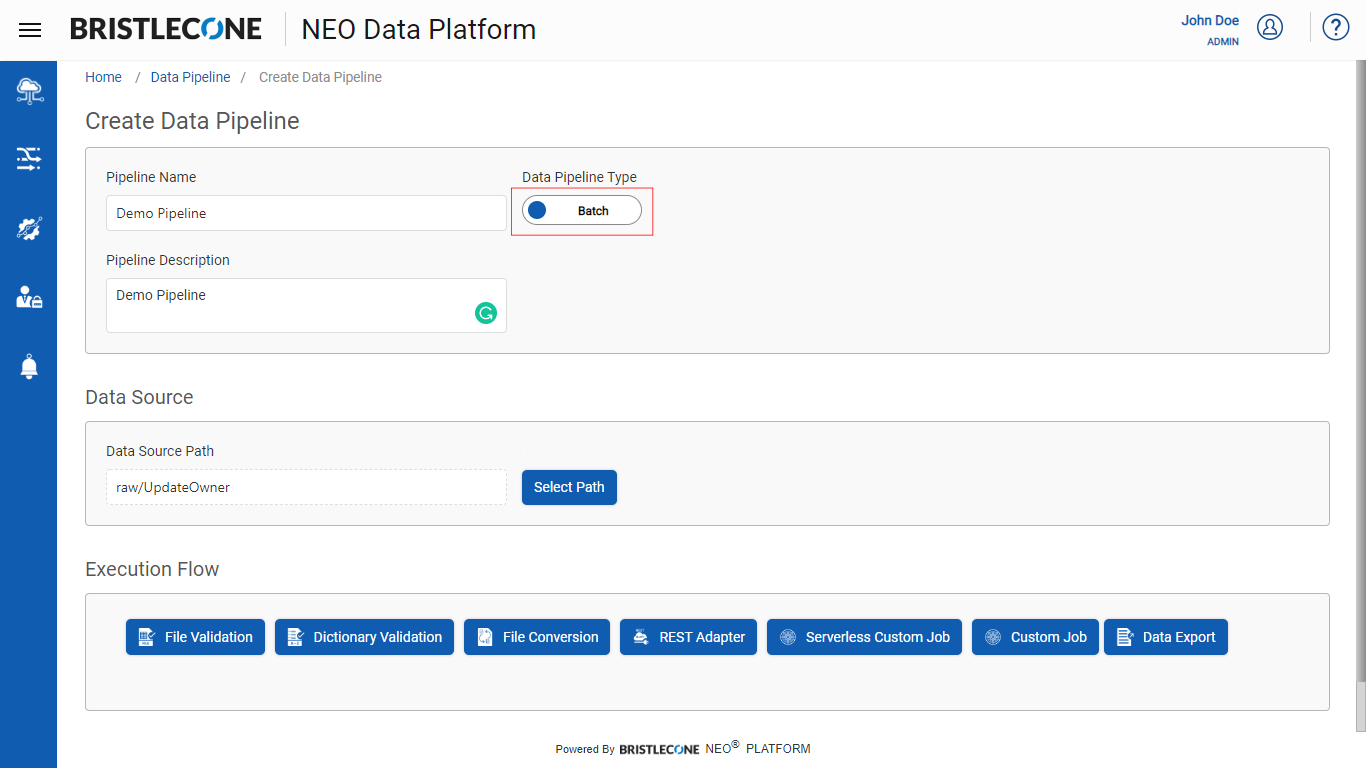
Step 1: Click on + and input the parameters as shown below
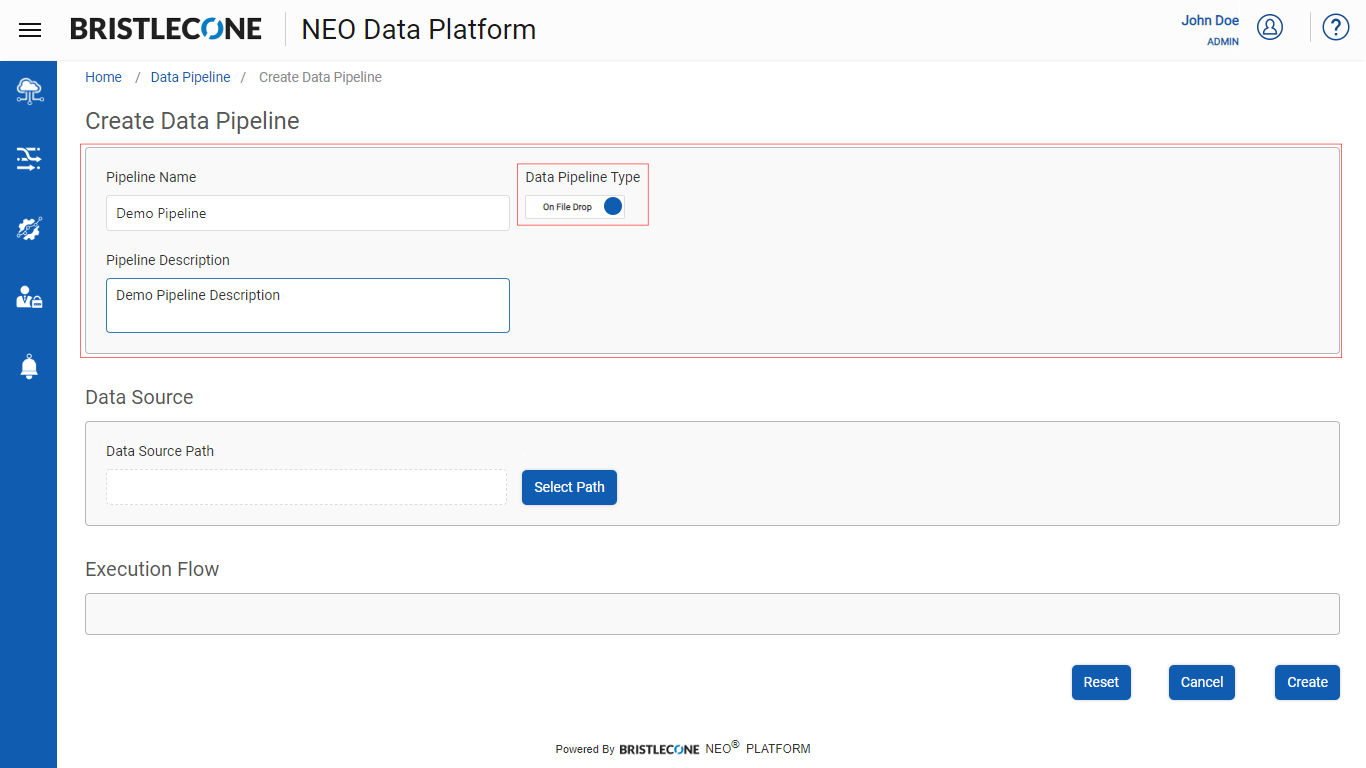
Step 2: Select the Data Source Path from Select Path as shown below
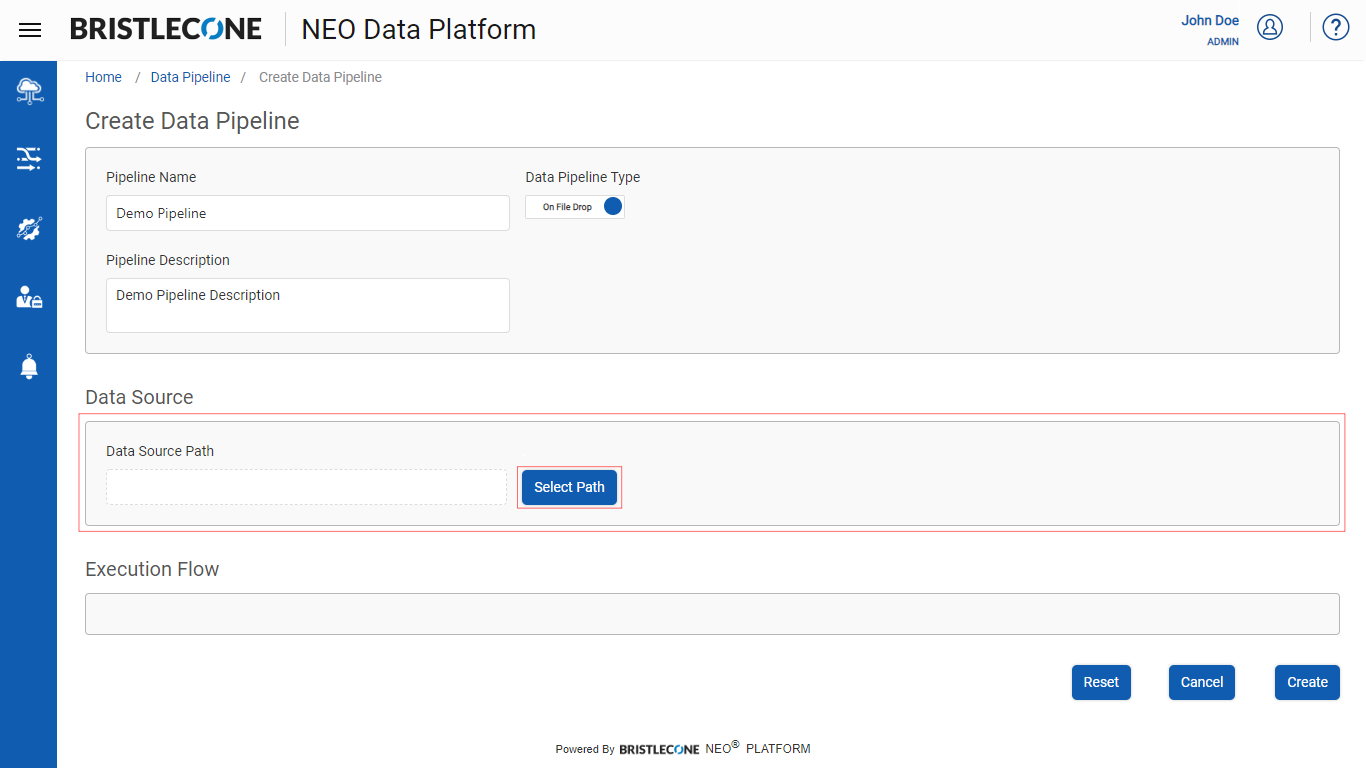
Select the Source Path from Data Org Directory
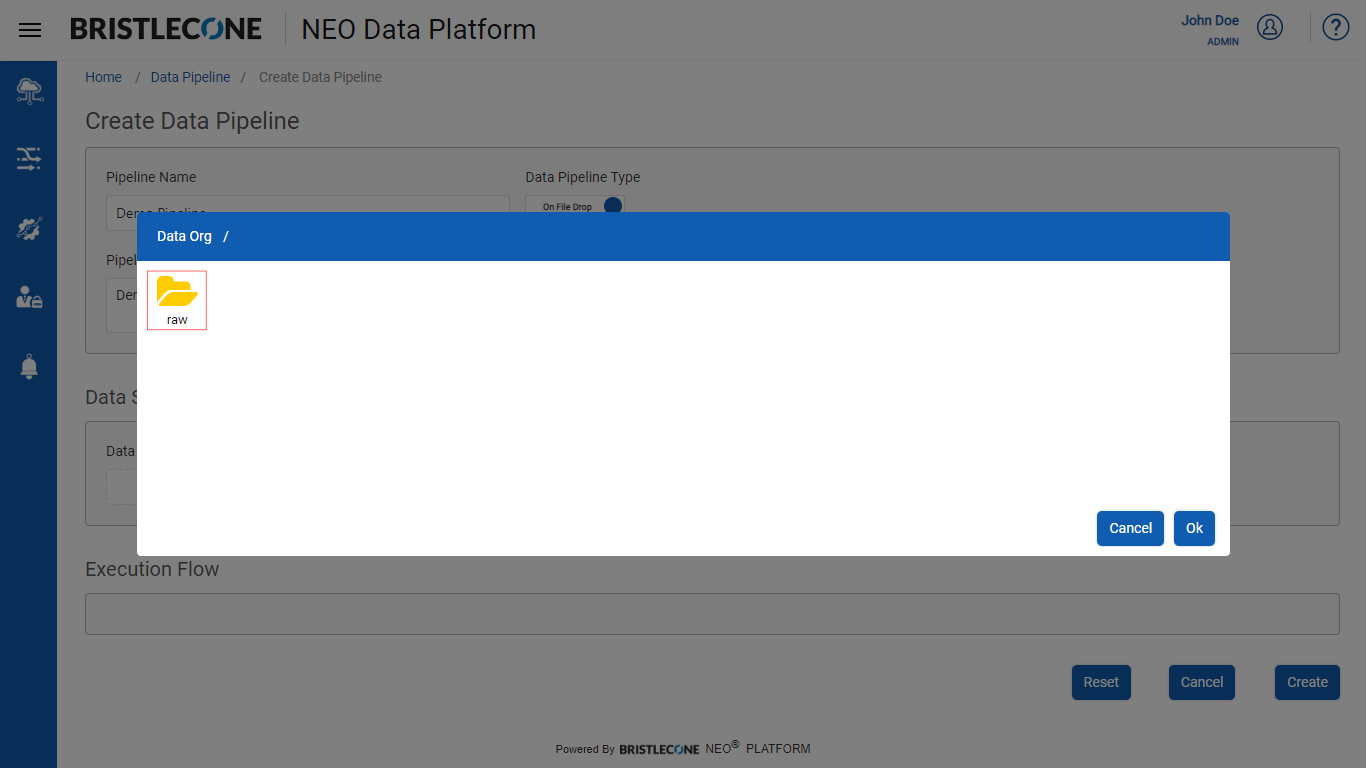
Select the folder from where pipeline execution will trigger and Click OK
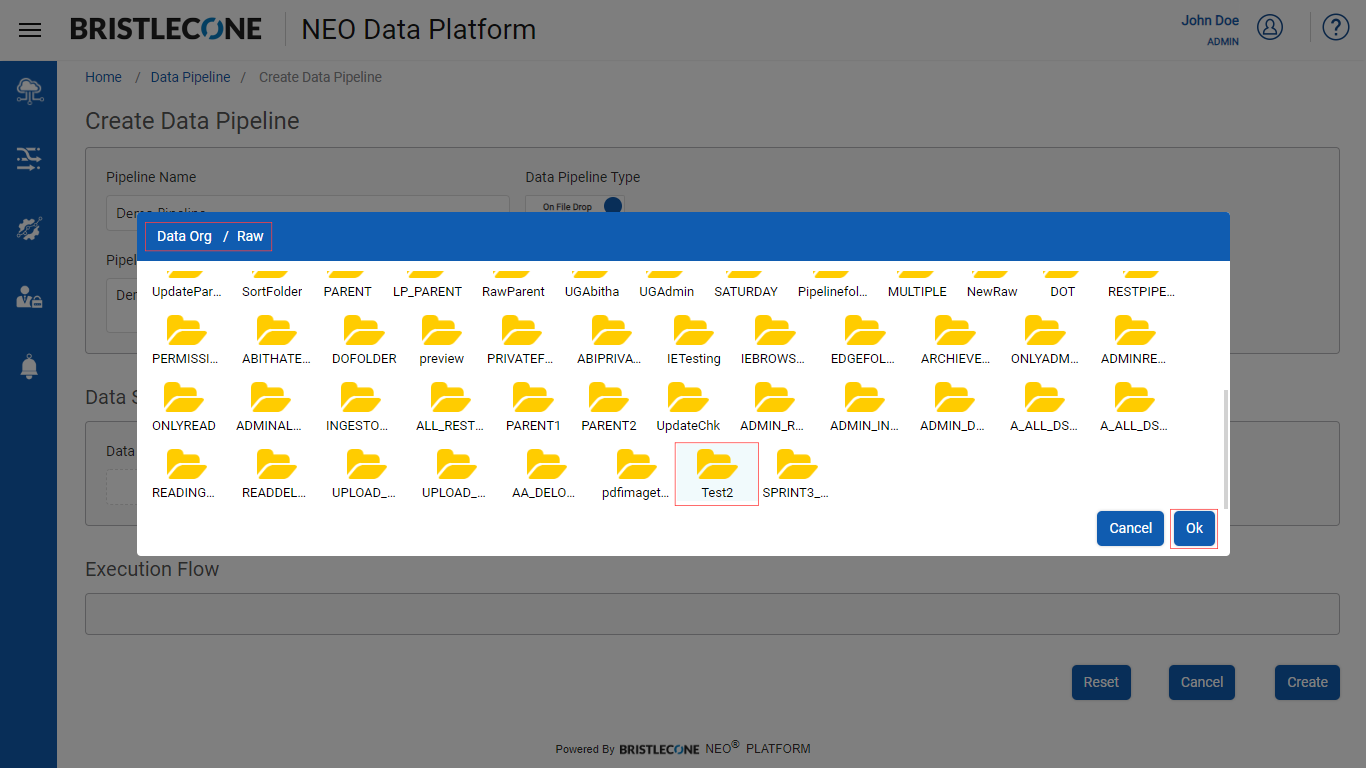
Step 3: Select the required steps in the Execution Flow to set up the Data Pipeline
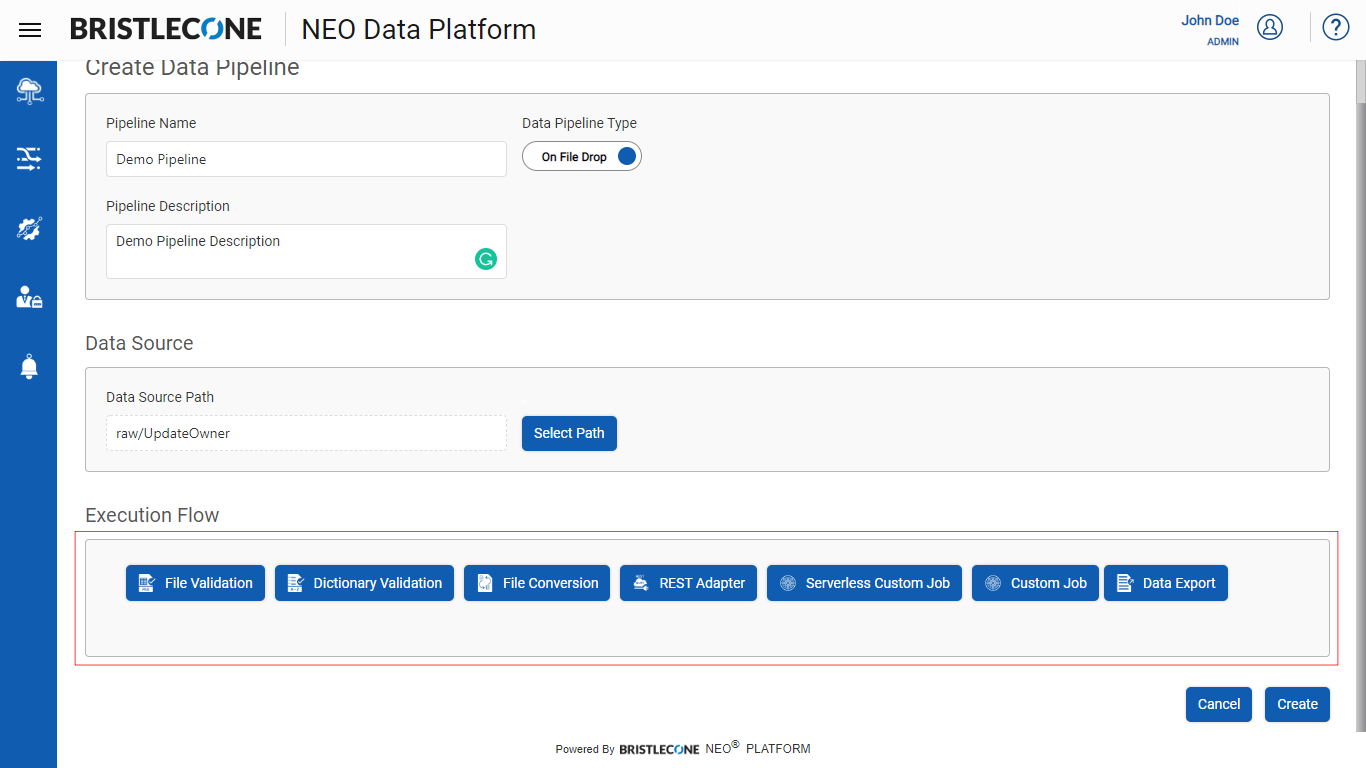
Step 4: Based on selected execution step, input the parameters as shown below and Click Create Button
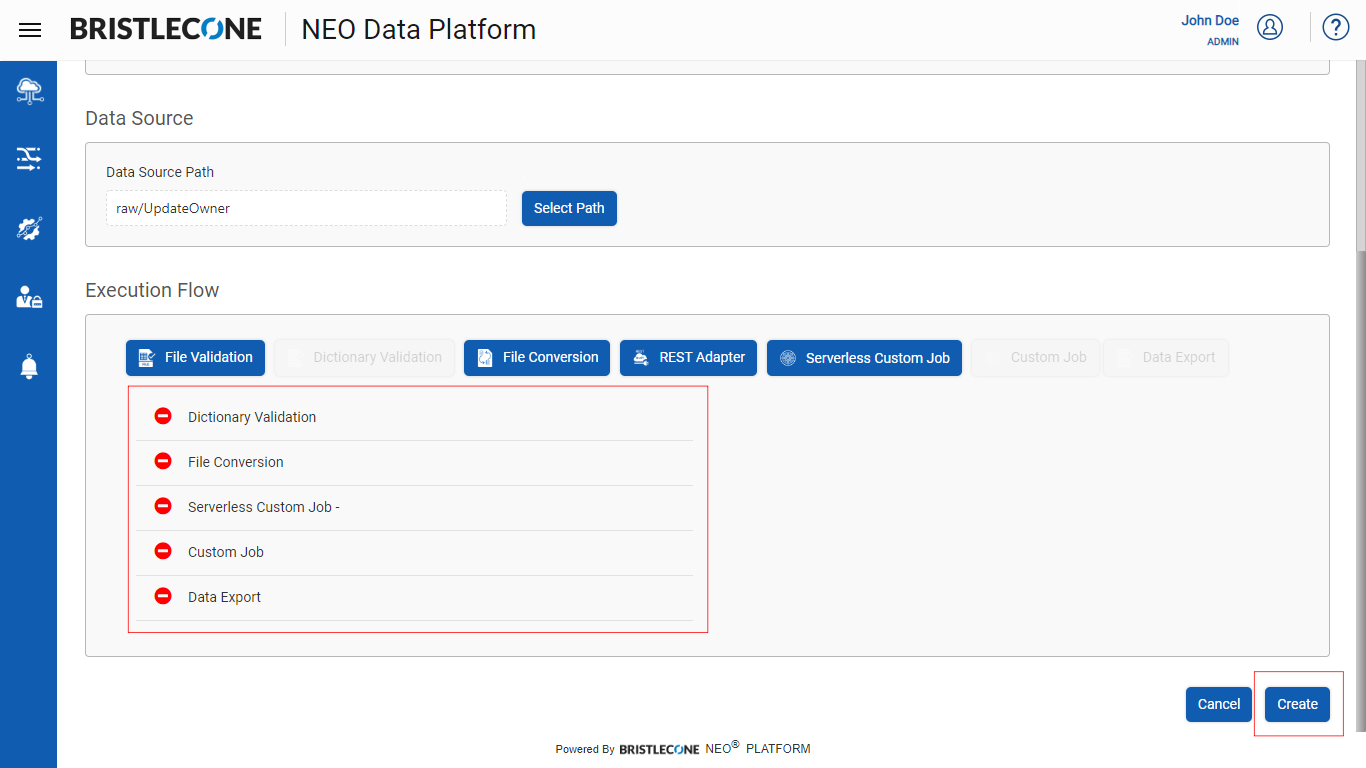
Note : Please refer to 1.3.5 Execution Flow section for expansive features and functionalities on Execution Flow
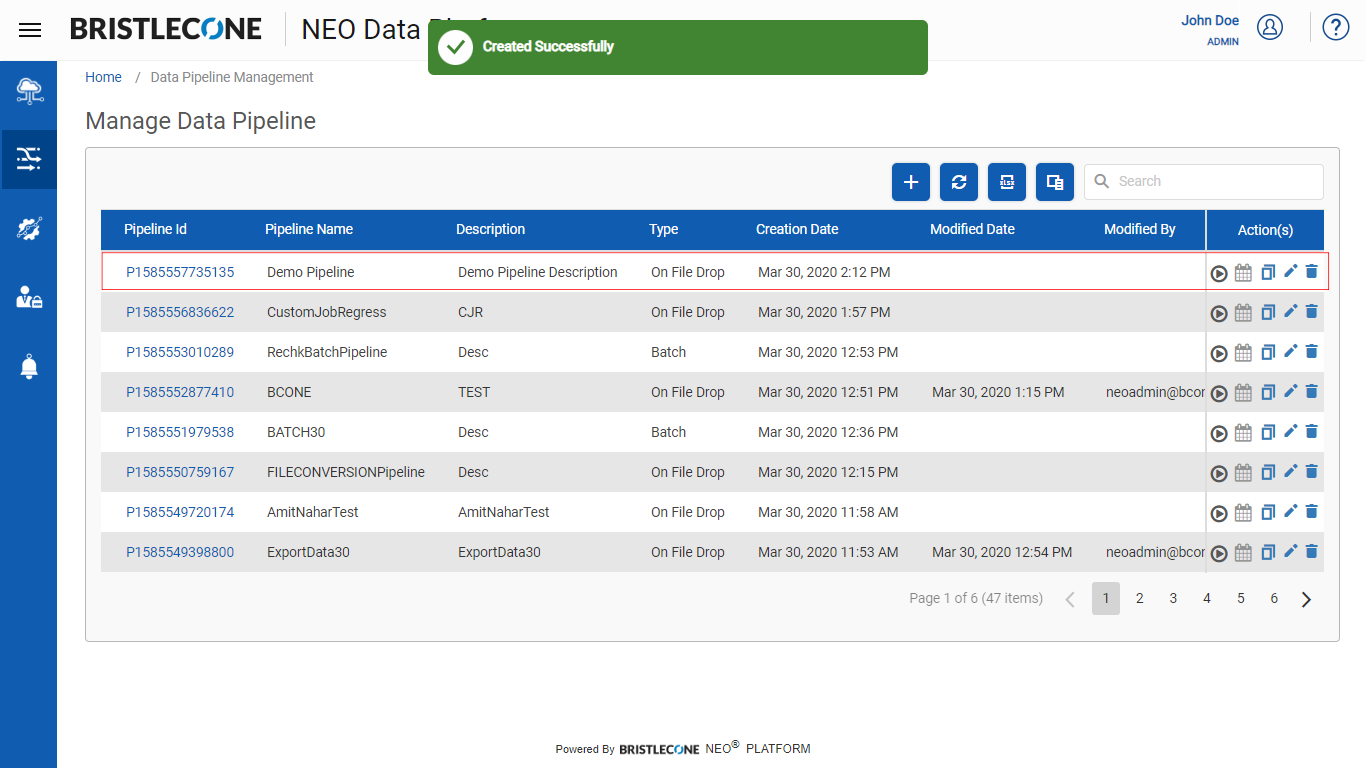
Once the Data Pipeline is created, it is populated in the Data Pipeline list as shown below
Designing a Data Pipeline : Batch Processing
Enables a Provider Data Scientist to configure and process batch [multiple] files as a part of the Data Pipeline Execution Flow
Note : Only one batch Data Pipeline execution is available at Bristlecone NEO® Platform
Following are the steps to execute a batch of files [ multiple files ] in the Bristlecone NEO® Platform :
Step 1: Create a Data Pipeline [Refer Create Data Pipeline section to know more ]
Note : Select the Batch mode using the toggle button as shown below
Hereafter the same step needs to follow as On File Drop
Data Pipeline List
The Data Pipeline list provides a tabulated information of the Data Pipelines through the following parameters:
- Data Pipeline ID: The ID of the Data Pipeline created
- Data Pipeline Name: Data Pipeline name
- Data Pipeline Description: Description about the Data Pipeline
Note : Type of Data Pipeline Processing: The platform supports Batch wise Data Pipeline processing
- Creation Date: The date on which the Data Pipeline was created
- Modified Date: The date on which the Data Pipeline was modified ( Last Modification Date)
- Modified by: Provides the email id of the person who modified the Data Pipeline
- Steps: The number of steps defined in the Execution Flow
- IsEnabled: isEnabled feature is disabled
- Actions: There are four actions that can be performed on a data pipeline.
- Run: Execute the Data Pipeline on demand
- Schedule: Schedule the Data Pipeline run.
- Edit: Edit the Data Pipeline
- Delete: Delete the Data Pipeline
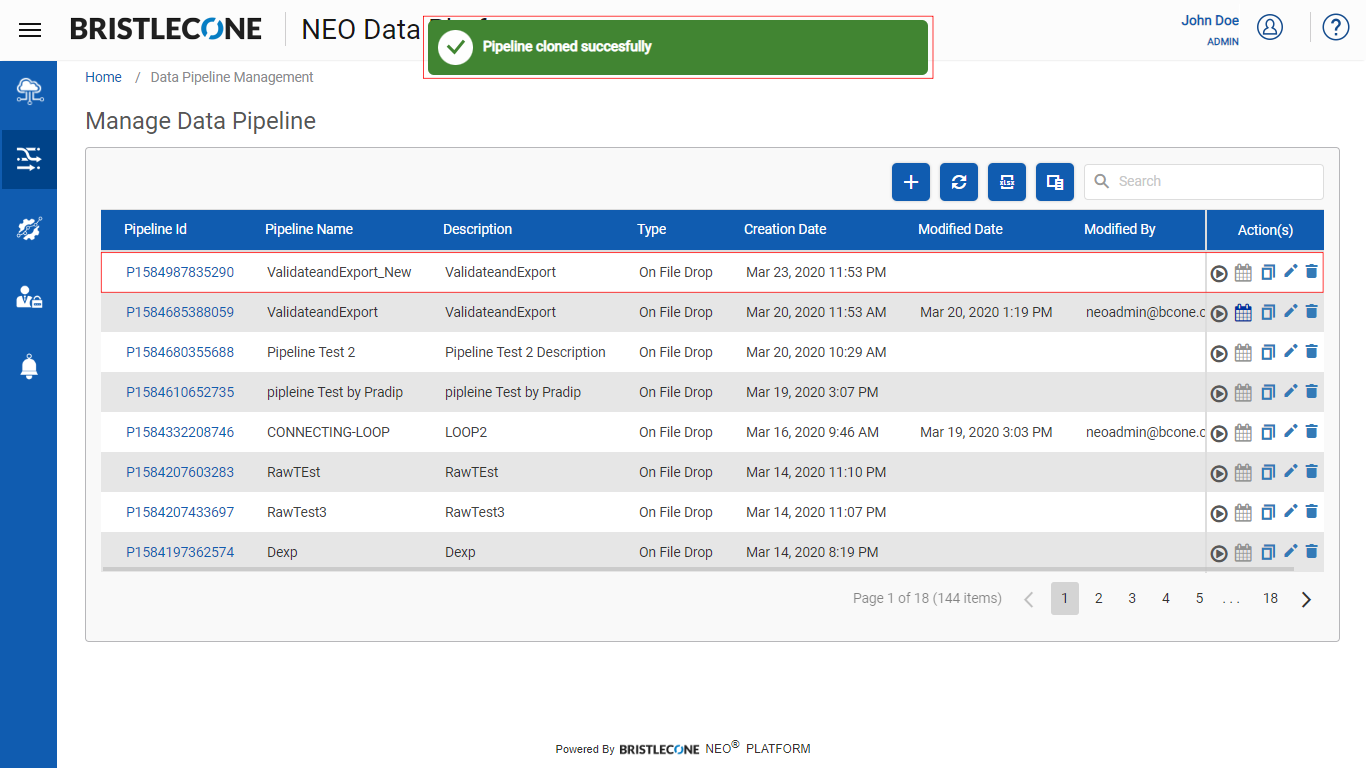
Clone Pipeline
This feature enables a Provider Data Scientist /Business Analyst/Data Engineer to copy/clone an existing pipeline
The following are the steps to clone an existing Data Pipeline:
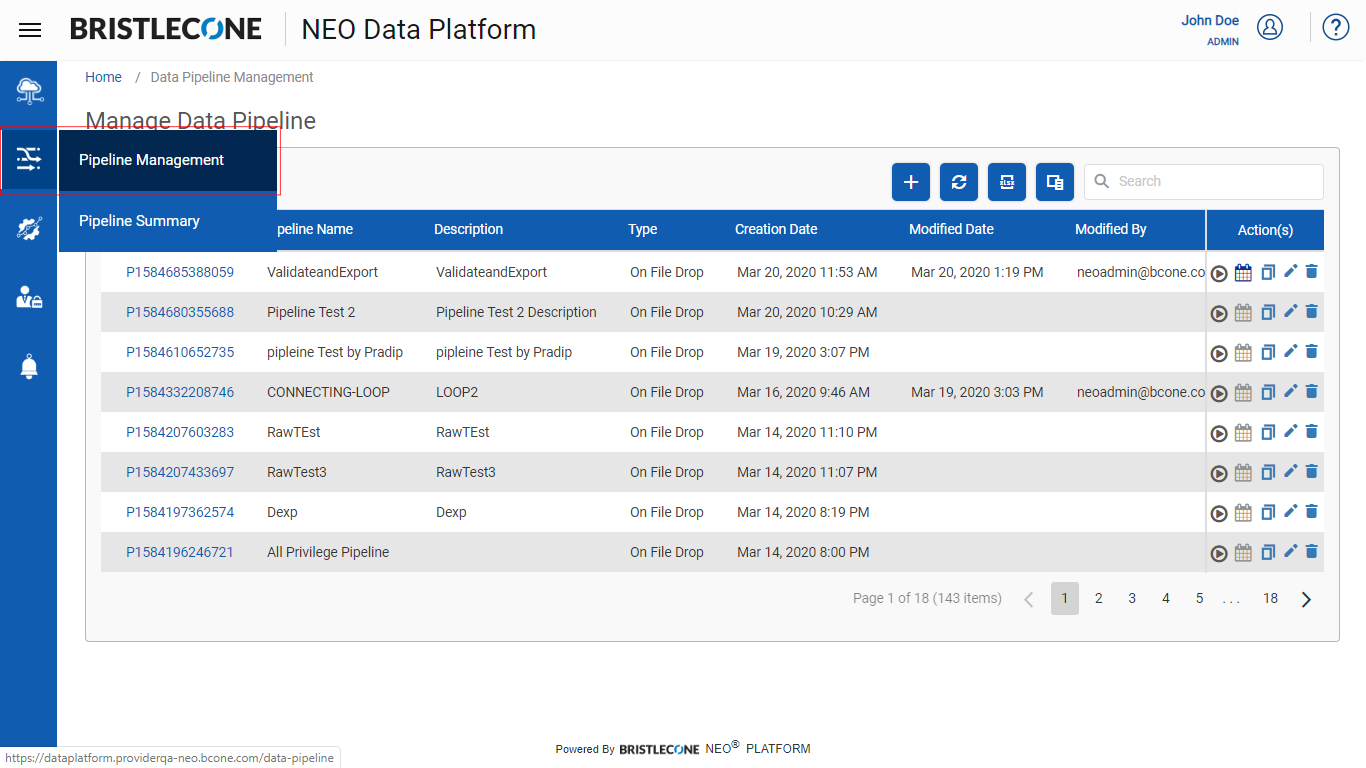
Step 1: Open Pipeline Management dashboard from the navigation panel as shown below
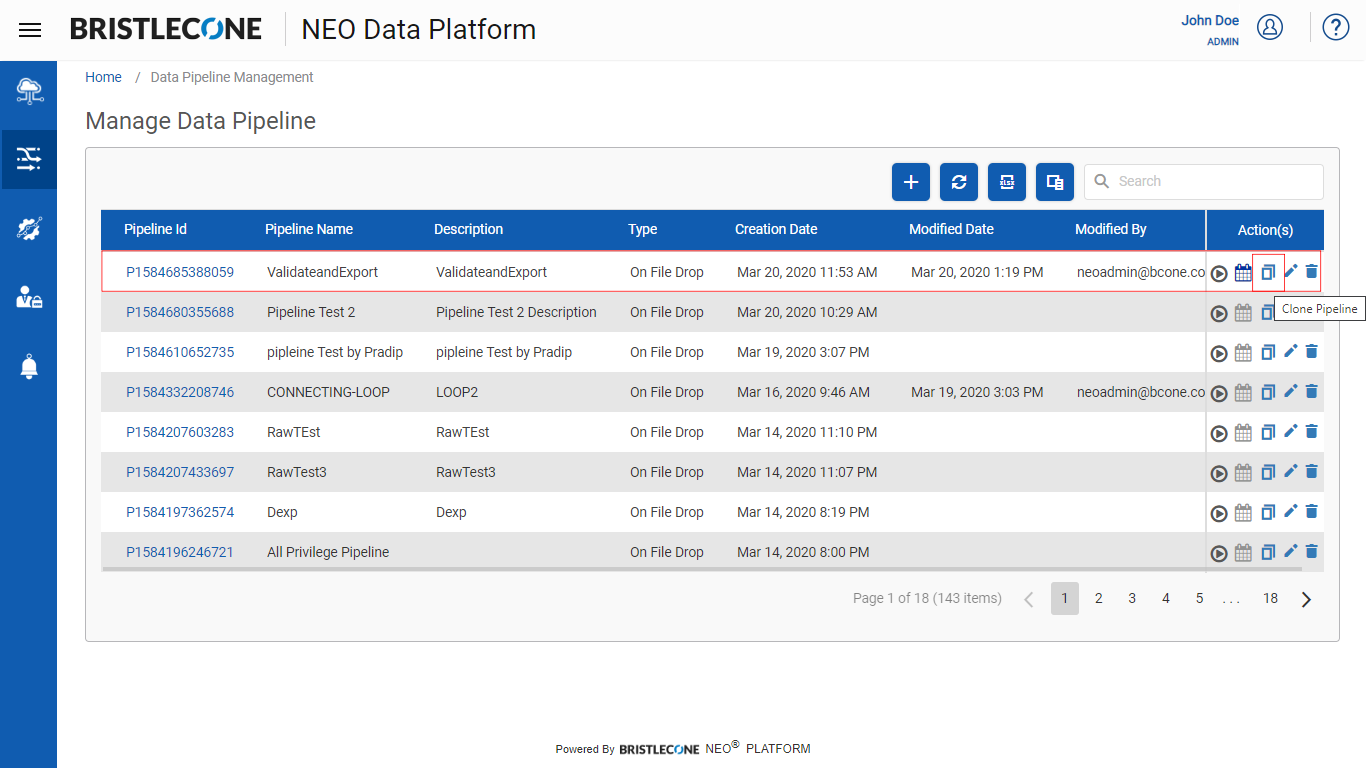
Step 2: Click on copy icon under Action(s) column of the respective Pipeline which needs to be cloned
Step 3: Rename the Pipeline Name and select a different Data Source Path
Note : Cloned Pipeline can not have same Pipeline name and same data source path. Only Pipeline Type and Execution Flow can remain same
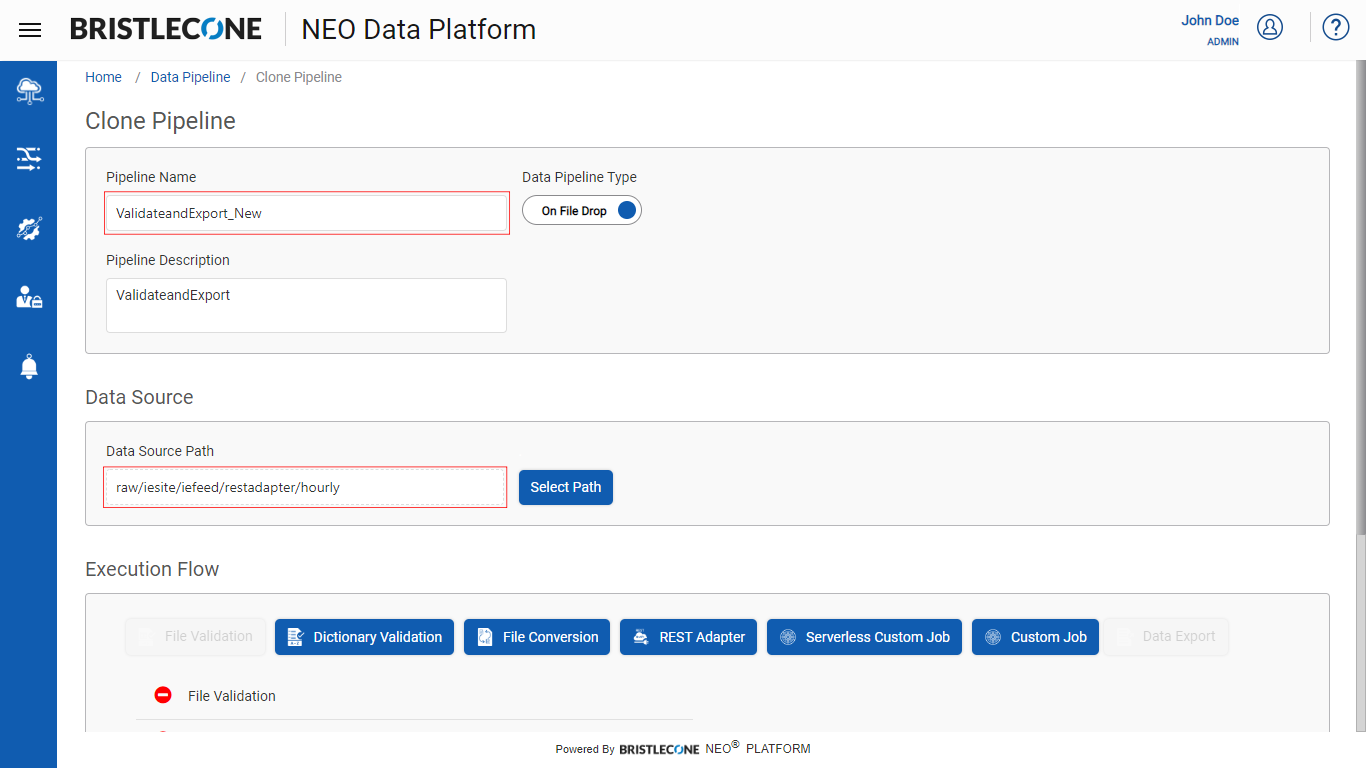
Step 4: Click on Clone button to complete cloning Pipeline
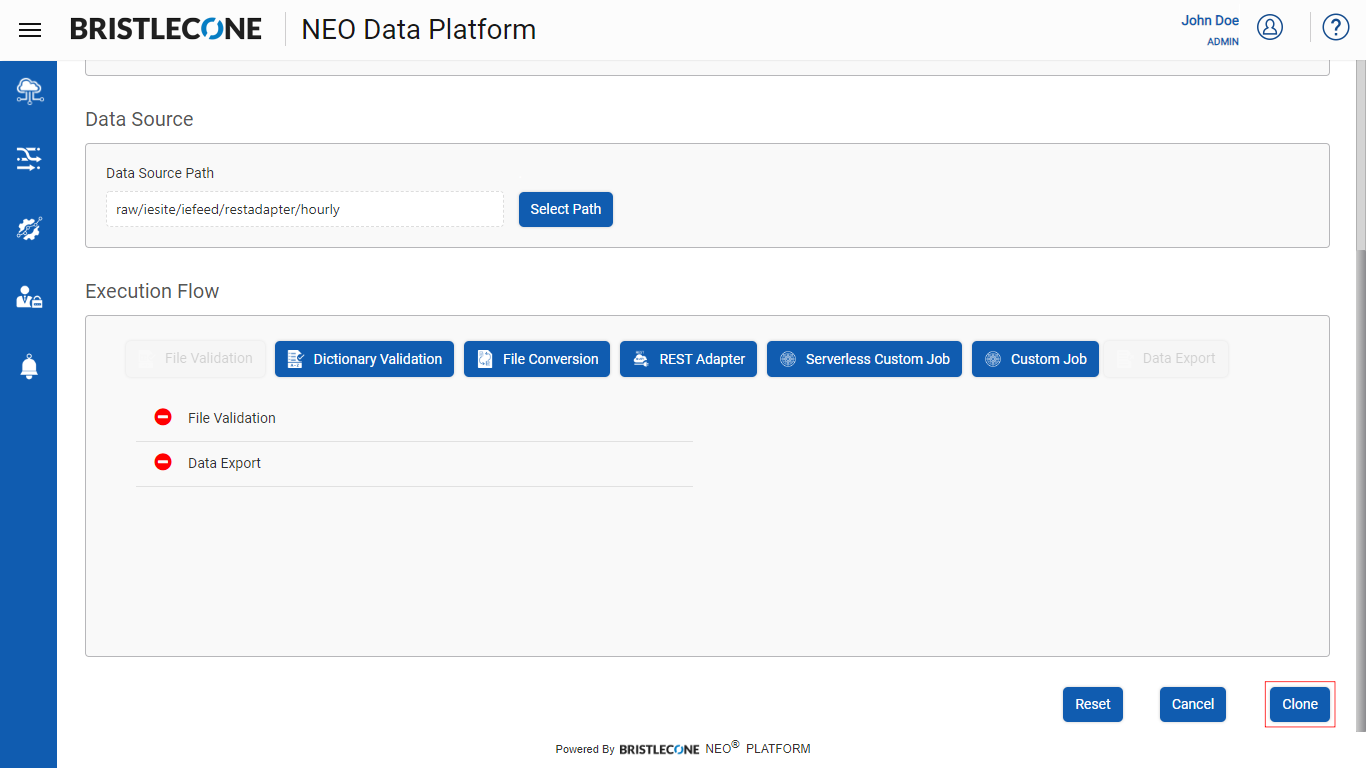
Post cloning, a successful notification will appear, and the new cloned pipeline will be listed as shown below